News
better business decisions
Posted 2 weeks ago | 8 minute read

Bring your own power: why the Energy Management System (EMS) is crucial
The concept of bring your own power (BYOP) is a core infrastructure strategy for data centres looking to get a grid connection. Under this model data centre operators build, own, and operate their own generation, storage.
The case for BYOP is well understood. Grid interconnection queues are long in most markets and data centre demand is growing faster than transmission and generation capacity can be added through conventional planning cycles. For a data centre, waiting for a utility queue position is not a viable strategy. The response has been to internalise the power supply. Build gas turbines, install a battery or solar on-site and sign a corporate power purchase agreement with a wind or solar developer. Each of these moves a piece of the energy problem inside the operator’s own perimeter. What it does not automatically do is make those assets work together, respond to grid signals correctly, or generate value between events.
A turbine, a battery, and a solar array sitting behind the same meter are not, by virtue of proximity, a co-ordinated system. Until something tells them how to behave as a portfolio, in real time, against an external signal, they are three separate pieces of hardware that share an interconnection point. The piece that connects them is an Energy Management System (EMS).
An EMS is the layer that takes a utility or ISO signal, understands what each asset can actually do in that moment (including state of charge, ramp rate, fuel availability, thermal headroom) and calculates the lowest-cost, most reliable way to hit the curtailment target across the whole portfolio simultaneously. Without that layer, a BYOP site has expensive optionality it cannot reliably exercise.
This means:
- operational control gets surrendered by default. If the EMS is a vendor’s bundled tool tied to one piece of hardware, the operator doesn’t actually control the portfolio; the vendor’s control logic does, within the limits of what that software was built to optimise for. With a system where multiple vendors are involved alongside equipment from different manufacturers, control fragments along hardware lines instead of consolidating around the site’s actual objective.
- data ownership erodes. Every dispatch decision, every state-of-charge curve, every response to a grid event generates data that has real value (for warranty claims, for proving compliance to a utility, for building a case to a regulator about reliability, for refining the next deployment). If that data lives inside a vendor’s proprietary platform rather than a system the operator controls, the operator is dependent on that vendor for access to the operating history of its own assets.
- long-term flexibility narrows to whatever the tool was designed for. A site commissioned to meet today’s curtailment obligations will likely want to participate in capacity markets, ancillary services, or demand response programmes tomorrow. A purpose-built EMS is designed to extend into those revenue streams, a bundled tool generally isn’t.
None of this becomes visible at the procurement stage, when the conversation is about megawatts, capital cost, and delivery timelines. It becomes visible the first time a curtailment notice arrives with a ten-minute window and the assets don’t respond as a co-ordinated whole.
Why this matters
Curtailment obligations are now appearing inside new interconnection agreements as a standard term. This means BYOP without a real EMS layer is a live risk.
The operator has to be able to prove, repeatedly and under time pressure, that it can respond to a utility or ISO signal correctly, reduce load by the requested amount, within the notice window, without breaching the SLAs the facility exists to serve. Notification windows for grid stress events are commonly measured in minutes, not hours. And across many utility territories, less than 5% of typical data centre load is currently considered curtailable, which puts pressure on extracting maximum, reliable flexibility from the assets that are available. This is where the limits of a single-resource approach become concrete:
- a battery-only response is capped by installed nameplate capacity. In a short, sharp emergency event it performs well, but in a sustained peak event running four hours or more, a battery-only system depletes and once drained, compliance stops
- a compute-only response (throttling, pausing, or shifting workloads) is cheaper to scale and can sustain meaningful load reduction for far longer, but it hits a hard ceiling defined by SLA headroom. Training jobs can be deferred, batch workloads can be paused and GPU and cooling power can be scaled down. But inference workloads serving live applications cannot pause without breaching customer commitments
Put those two modes side by side and the shape of the real solution becomes obvious: orchestration that sees both physical assets and compute flexibility and splits every curtailment call between them dynamically, in real time, based on what each can actually deliver in that moment. That orchestration layer is the EMS. It is not a feature of the battery system or a feature of the compute platform. It has to sit above both, with visibility into both, calculating the optimal split call by call.
What co-optimised orchestration actually looks like under pressure
It’s worth being concrete about what this looks like in practice.
Take a PJM curtailment event from June 2025, when the grid hit its highest peak since 2011 and dispatched roughly 4,000MW of demand response across the Mid-Atlantic and Dominion zones. Modelled against a representative 100MW data centre campus with a 470MWh battery system, a compute-control response alone could sustain 33MW of flexibility for the full seven-hour event; short of what a 100 MW site might be asked to deliver, and it leaves the site drawing meaningfully from the grid throughout. Pair that same 33MW of compute flexibility with 67MW from the battery system, co-optimised by an EMS layer that’s continuously calculating the split, and the result is zero net grid draw for the entire seven-hour window. Same physical assets in both scenarios. The difference is entirely in the orchestration.

Source: GridBeyond
The pattern holds across different event types, because each one stresses a different part of the system:
- In an emergency curtailment with a notice window of minutes rather than hours, the battery has to bridge the response gap in milliseconds while compute load sheds a meaningful share within the first thirty seconds, together hitting the full target comfortably inside the utility’s notice window
- In a multi-hour peak event running eight hours or more, compute flexibility carries the bulk of the sustained reduction while the battery handles the ramps and transitions a compute-only response can’t smooth on its own. This is precisely the scenario where a battery-only system would have failed: the hours-three-to-five depletion window that compute flexibility is specifically there to cover
- In jurisdictions with mandatory remote curtailment thresholds (Texas SB6 being the clearest current example, applying to loads above 75 MW) a remote signal can trigger battery discharge and compute throttling simultaneously, meeting the legal requirement without taking the facility offline. The alternative, for a site without co-ordinated orchestration, is a choice between full shutdown and non-compliance
- And in a scheduled, day-ahead market event, the orchestration layer pre-positions. With 24 hours’ notice, deferrable compute jobs get shifted ahead of the window and the battery charges to full state of charge, so that when an event arrives, the response captures capacity and ancillary service revenue on top of meeting the obligation while SLAs hold throughout
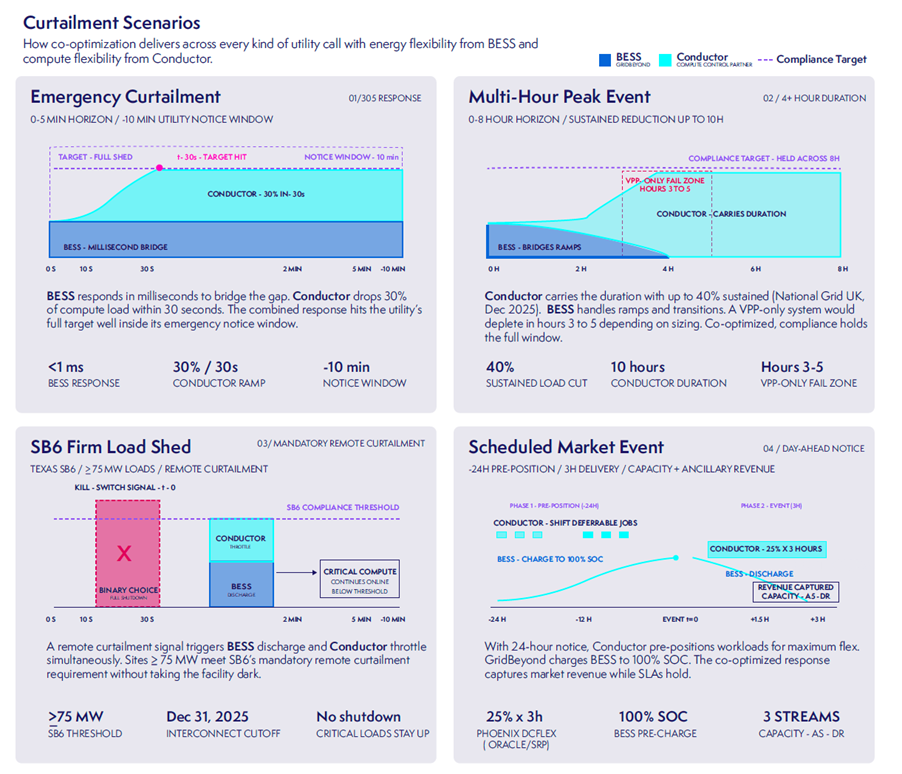
Source: GridBeyond
What is consistent across all scenarios is that no single resource is ever asked to do the whole job, because no single resource can. The EMS is what decides, continuously and automatically, how the load gets split and a co-optimised approach combining battery and compute flexibility has been shown to deliver 100% of curtailment events in full, against roughly 30%–50% delivered by either resource used alone: that is the orchestration gap.
In markets where compliance has stopped being upside and has become the floor the orchestration gap brings significant risks. The EMS is a comparatively small line item by cost, but it determines whether that capital expenditure produces a compliant, revenue-generating asset or an expensive set of components that can’t reliably hit a utility’s target when the call comes in. Underinvesting in orchestration doesn’t save money proportionate to the saving; it puts the return on the entire hardware stack at risk.
BYOP answers the question of where the power comes from. The EMS answers the harder question: what the operator can actually do with it, the moment it matters most.

Energy Management System Flyer
Through intelligent, real-time energy design, forecasting, optimisation, and control, and innovative funding options, you can unlock the full potential of your energy strategy and accelerate your business towards its sustainability goals.
Learn moreLatest energy insights
-

14 July 2026
2 minute read
Government urged to cut business energy bills by moving green levies
Read More -

8 July 2026
3 minute read
Electricity system “structurally failing manufacturers”, says Make UK
Read More -
2 July 2026
8 minute read
Bring your own power: why the Energy Management System (EMS) is crucial
Read More


